March 2020 to October 2021
Starting in March 2020 when we went into “work from home” to combat covid-19, I held a virtual “coffee” session with everyone from my extended team invited until the end of October 2021.
One of the elements of the session, almost every day, was a ‘quote of the day’, some inspiring words that I found somewhere. I gathered these from many websites, from friends I know, from experiences I had.
I wish I’d kept the complete list of places where I found each quotation. Many of these were on multiple sites. I cannot vouch for the attribution of every single quote. But any one where I did some research about the individual did confirm that they said it.
The complete list, in the order that they were shared in our coffee chats. My comments in italics.
Quotes:
“Every storm runs out of rain” Maya Angelou (American author and poet)
The very first of our Coffee in the Clouds quotes of the day. Such a beautiful way to say that challenges – even big ones – do pass. Many quotes by Maya Angelou follow; one that I never used but that is among my favourite of hers is “When you know better, you do better.”
“The quest for certainty blocks the search for meaning. Uncertainty is the very condition to impel man to unfold his powers.” Erich Fromm
“I find hope in the darkest of days, and focus in the brightest. I do not judge the universe.” The Dalai Lama.
“A problem is a chance for you to do your best” Duke Ellington
“Skill and confidence are an unconquered army” George Herbert, a Welsh poet from the 1600s.
“Resilience is accepting your new reality, even if it’s less good than the one you had before. You can fight it, you can do nothing but scream about what you’ve lost, or you can accept that and try to put together something that’s good.” Elizabeth Edwards. She wrote a book on resilience. An American lawyer and wife of former presidential candidate John Edwards
“He knows not his own strength who hath not met adversity.” William Samuel Johnson American statesman, he signed the US Constitution
“Obstacles don’t have to stop you. If you run into a wall, don’t turn around and give up. Figure out how to climb it, go through it, or work around it.” Michael Jordan
“In the middle of difficulty lies opportunity” Albert Einstein
“Things turn out the best for the people who make the best of the way things turn out.” John Wooden. American basketball player and head coach at the University of California, Los Angeles. Nicknamed the “Wizard of Westwood,” he won ten NCAA national championships in a 12-year period as head coach at UCLA, including a record seven in a row.
“The human capacity for burden is like bamboo- far more flexible than you’d ever believe at first glance.” ― Jodi Picoult, author of My Sister’s Keeper
“Persistence and resilience only come from having been given the chance to work through difficult problems.” Gever Tulley
“What stands in the way becomes the way.” Roman Emperor Marcus Aurelius. One of the great stoic philosophers.
“It’s your reaction to adversity, not adversity itself that determines how your life’s story will develop.” Dieter F. Uchtdorf. Pilot, Author and senior church member in LDS
“Do not judge me by my success, judge me by how many times I fell down and got back up again.” ― Nelson Mandela
“Our greatest glory is not in never falling, but in rising every time we fall.” Confucius
“Rock bottom became the solid foundation in which I rebuilt my life.” J.K. Rowling
“I tried and failed. I tried again and again and succeeded.” Gail Borden.
Researching Borden uncovered one of those fascinating sets of connections about someone you’ve probably never heard of…. Gail Borden was a Texan who lived in the 1800s, a man of many skills. Among those, he was surveyor, newspaper editor and one of the people who planned the original city of Houston. If he is famous today at all, it would be as the “inventor” of condensed milk. Condensed milk could be kept much longer than fresh milk. He was also related to both Lizzie Borden, the accused axe murderer, and Canadian Prime Minister Sir Robert Borden. Which implies that Sir Robert and Lizzie were related.
What I like about this quote is the importance of persistence. So many other great attributes fail when not tied together with persistence. Although I also believe the quote which is often attributed to Einstein that ‘doing the same thing over and over and expecting a different outcome is the definition of insanity’, so it’s important to make sure you are persistent but also learning and adapting.
“If you’re going through hell, keep going.” Sir Winston Churchill.
Lots of quotes from Churchill appear below. This particular one I’ve used many times in sessions on ‘how to manage a troubled project’ or during troubled projects. When you put it this way, it seems kind of obvious. Don’t stop in the bad place!
“No matter how bleak or menacing a situation may appear, it does not entirely own us. It can’t take away our freedom to respond, our power to take action.” Ryder Carroll
“On the other side of a storm is the strength that comes from having navigated through it. Raise your sail and begin.” Gregory S. Williams. Novelist – best known as the author of Fatal Indemnity
“When we learn how to become resilient, we learn how to embrace the beautifully broad spectrum of the human experience.” ― Jaeda Dewalt author, photographer author of “Chasing Desdemona”
“Courage doesn’t always roar. Sometimes courage is the quiet voice at the end of the day saying ‘I will try again tomorrow’.” ― Mary Anne Radmacher; writer, artist, author of “Courage Doesn’t Always Roar”
“To be really great in little things, to be truly noble and heroic in the insipid details of everyday life, is a virtue so rare as to be worthy of canonization.” Harriet Beecher Stowe. Author of Uncle Tom’s Cabin. American Abolitionist.
“Do your little bit of good where you are; its those little bits of good put together that overwhelm the world.” Desmond Tutu
“I alone cannot change the world, but I can cast a stone across the water to create many ripples.” Mother Teresa
“I’ve learned that people will forget what you said, people will forget what you did, but people will never forget how you made them feel.” Maya Angelou
“Whether you think you can or you think you can’t, you’re right.” Henry Ford
“Perfection is not attainable, but if we chase perfection we can catch excellence” Vince Lombardi
“Life is 10 percent what happens to me and 90 percent of how I react to it.” Charles Swindoll. A US evangelical pastor.
“I can’t change the direction of the wind, but I can adjust my sails to always reach my destination.” Jimmy Dean, American country music singer, and TV host.
“Nothing is impossible, the word itself says ‘I’m possible’!” Audrey Hepburn
“I’ve missed more than 9000 shots in my career. I’ve lost almost 300 games. Twenty-six times I’ve been trusted to take the game winning shot and missed. I’ve failed over and over and over again in my life. And that is why I succeed.” Michael Jordan
“Strive not to be a success, but rather to be of value.” Albert Einstein
“I am not a product of my circumstances. I am a product of my decisions.” Stephen Covey
While this is true a lot of the time for a lot of us, it’s also true that a lot of people are trapped by birth and circumstance. It’s a good quote for a high performing team, that’s stumbling, it’s a bad quote for someone trapped in a war zone or in the middle of famine.
“When everything seems to be going against you, remember that the airplane takes off against the wind, not with it.” Henry Ford
“The most common way people give up their power is by thinking they don’t have any.” Alice Walker. Novelist poet. Most famous for writing The Color Purple. Walker won the Pulitzer Prize for fiction.
“The most difficult thing is the decision to act, the rest is merely tenacity.” Amelia Earhart. Aviator.
Earhart was the first women to cross the Atlantic by plane. Holder of multiple early aviation records. One of the most famous missing people in the world, lost over the Pacific with her navigator while trying to become the first person to circumnavigate the world by plane. This quote combines nicely with the previous one. As a child I had a poster in my bedroom saying “Not to decide is to decide.” It’s better to make a decision and move forward than to dither.
“It is during our darkest moments that we must focus to see the light.” Aristotle Onassis, Greek shipping magnate.
“Don’t judge each day by the harvest you reap but by the seeds that you plant.” -Robert Louis Stevenson. Author of Treasure island, Kidnapped, Dr Jekyll. Stevenson died at age 44
“Life’s most persistent and urgent question is: What are you doing for others?” Martin Luther King, Jr
“A riot is the language of the unheard.” Martin Luthor King, Jr
“The question isn’t who is going to let me; it’s who is going to stop me.” Ayn Rand
“If you hear a voice within you say, ‘You cannot paint,’ then by all means paint and that voice will be silenced.” Vincent Van Gogh
“I have been impressed with the urgency of doing. Knowing is not enough; we must apply. Being willing is not enough; we must do.” Leonardo da Vinci
“Remember that not getting what you want is sometimes a wonderful stroke of luck.” Dalai Lama.
“A person who never made a mistake never tried anything new.” Albert Einstein
“When one door of happiness closes, another opens, but often we look so long at the closed door that we do not see the one that has been opened for us.” Helen Keller
“When I was 5 years old, my mother always told me that happiness was the key to life. When I went to school, they asked me what I wanted to be when I grew up. I wrote down ‘happy.’ They told me I didn’t understand the assignment, and I told them they didn’t understand life.” John Lennon
Lennon definitely said this. I’ve always wondered if he actually did have that conversation as a child. It sounds too good to be true.
“The only person you are destined to become is the person you decide to be.” Ralph Waldo Emerson
“Everything you’ve ever wanted is on the other side of fear.” George Addair
“Be the change you want to see” Gandhi (via colleague Dave Bataille)
“We can easily forgive a child who is afraid of the dark; the real tragedy of life is when men are afraid of the light.” Plato
“Nothing will work unless you do.” Maya Angelou
“Believe you can and you’re halfway there.” Theodore Roosevelt
Also, Sondheim in West Side Story’s “Somewhere”
“What we achieve inwardly will change outer reality.” Plutarch. A platonic philosopher in first century best known for his work in biography … Parallel Lives
“Control your own destiny or someone else will.” Jack Welch
“To improve is to change, so to be perfect is to change often.” Winston Churchill
“The role of a leader is to define reality and offer hope.” Napoleon
I often use this when teaching about leadership or program management or helping the leaders on my team understand their role. One of the best definitions of leadership ever. But should it be ‘describe reality’ or ‘define reality’? ‘Define reality’, which is the quote, sounds more like Napoleon – creating what he wanted by force of will. But it seems to me that being honest about where we are, being willing to admit the challenges, and then offer the hope, the roadmap, the vision on how to get to somewhere better is true leadership.
“Once you choose hope, anything is possible.” Christopher Reeve
“Faith is taking the first step even when you don’t see the whole staircase.” Martin Luther King Jr.
“Every man should ask himself each day he is not too readily accepting negative solutions.” Winston Churchill
“Nothing is forever, not even our problems.” Charlie Chaplin
“The three most important ways to lead people are by example, by example, by example.” Albert Schweitzer
Also ways four through ten.
“When the eagles are silent the parrots begin to jabber.” Winston Churchill
“The most wasted day of all is that on which we have not laughed.” Nicolas Chamfort. French writer, who died in 1794. Chamfort was also secretary to the sister of Louis XVI.
“When I’m sometimes asked when will there be enough [women on the supreme court]? And I say ‘When there are nine.’ People are shocked. But there’d been nine men, and nobody’s ever raised a question about that” Ruth Bader Ginsburg.
I found this quote and the next one for the session right after Justice Ginsburg died. A great jurist and fighter for equality, and this is a great reminder about how far we are from that goal not just in the US but everywhere.
“Fight for the things that you care about, but do it in a way that will lead others to join you.” Ruth Bader Ginsburg.”
“Too many of us are not living our dreams because we are living our fears.” -Les Brown. American motivation speaker. Catch phrase “It’s possible”; He was married to Gladys Knight.
“Whatever the mind of man can conceive and believe, it can achieve.” Napoleon Hill. US self-help author, died in 1970. Author of Think and Grow Rich.
“Courage is what it takes to stand up and speak. It is also what it takes to sit down and listen.” Winston Churchill
Having read Manchester’s three volume biography of Churchill, I’m not entirely sure he had this particular form of courage!
“Have faith, have hope, have courage and carry on. If we do that we will be tremendously successful.” Howard Boville (became head of IBM cloud in 2021)
“Baseball is a game of confidence, and overcoming failures and fears. That’s what life’s about to.” Yogi Berra
“Twenty years from now you will be more disappointed by the things that you didn’t do than by the ones you did do. So throw off the bowlines. Sail away from the safe harbor. Catch the trade winds in your sails. Explore. Dream. Discover.” Mark Twain
“Continuous effort – not strength or intelligence – is the key to unlocking our potential.” Winston Churchill
“The only way a leader can withstand the gale force winds of change is by relying on his or her deep, healthy roots.” Bob Rosen, author of Grounded
“Rivers do not drink their own water; trees do not eat their own fruit; the sun does not shine on itself and flowers do not spread their fragrance for themselves. Living for others is a rule of nature. We are all born to help each other. No matter how difficult it is… life is good when you are happy; but it is much better when others are happy because of you.” Pope Francis
“You have to give 100 percent in the first half of the game. If that isn’t enough, in the second half, you have to give what’s left.” Yogi Berra
“One always measures friendships by how they show up in bad weather.” Winston Churchill
“You shouldn’t give circumstances the power to rouse anger, for they don’t care at all.” Marcus Aurelius
“Nobody can be all smiley all the time, but having a good, positive attitude isn’t something to shrug off.” Yogi Berra
“Be yourself; everyone else is already taken.” Oscar Wilde
“Three things in human life are important. The first is to be kind. The second is to be kind. And the third is to be kind.” Henry James. American author from the 1880s
“We may have all come on different ships, but we are all in the same boat now.” Martin Luther King Jr.
“Attitude is a little thing that makes a big difference.” Winston Churchill
“Little things are big.” Yogi Berra
As long as you have confidence in your heart, you will never be defeated. Li Ning, CEO of Li Ning Sports.
“Live all you can; it’s a mistake not to. It doesn’t so much matter what you do in particular, so long as you have your life. If you haven’t had that what have you had?” Henry James
“Success is the ability to go from one failure to another with no loss of enthusiasm.” Winston Churchill
“There are going to be priorities and multiple dimensions of your life, and how you integrate that is how you find happiness.” Denise Morrison, CEO of Campbell’s soups
“There are a lot of things in life you can’t control, but how you respond to things, that you CAN control.” Yogi Berra
“Only in the darkness can you see the stars.” Martin Luthor King Jr
“You must put your head into the mouth of the lion if the performance is to be a success” Winston Churchill
“Be not afraid of life. Believe that life is worth living, and your belief will help create the fact.” Henry James
“Be tolerant with others and strict with yourself.” Marcus Aurelius
“Every day you may make progress. Every step may be fruitful. Yet there will be stretching out before you an ever-lengthening, ever-ascending, ever-improving path. You know you will never get to the end of the journey. But this, so far from discouraging, only adds to the joy and glory of the climb.” Winston Churchill
The eminently quotable Churchill showed up a lot on our calls. A more controversial figure than I realized when I was young, there is no question of his ability to seize the moment, inspire his country and the world with a brilliant line. Not so much a ‘project’-applicable quote where there are milestones and deliverables. But in the long run, it isn’t the destination that matters, it’s the journey.
“There are far, far better things ahead than any we leave behind.” CS Lewis
“I never dreamed we’d accomplish so much, but hunger accomplishes a lot of things.” Yogi Berra
“What is character but the determination of incident? What is incident but the illustration of character?” Henry James.
“I skate to where the puck is going to be, not to where it is.” Wayne Gretzky
“Next to trying and winning, the best thing is trying and failing.” Lucy Maud Montgomery in Anne of Green Gables
“It doesn’t make sense to hire smart people and then tell them what to do; we hire smart people so they can tell us what to do.” Steve Jobs
“Feminism isn’t about making women stronger. Women are already strong. It’s about changing the way the world perceives that strength.” GD Anderson
“Mental pain is less dramatic than physical pain, but it is more common and also more hard to bear. The frequent attempt to conceal mental pain increases the burden: it is easier to say ‘My tooth is aching’ than to say ‘My heart is broken.’” CS Lewis
“I try to accomplish something each day.” – Yogi Berra
“Learn avidly. Question it repeatedly. Analyze it carefully. Then put what you have learned into practice intelligently.” — Confucius
“Success is about dedication. You may not be where you want to be or do what you want to do when you’re on this journey. But you’ve got to be willing to have vision and foresight that leads you to an incredible end.” Usher
“Selling starts when the customer says ‘No’. Up till then it is just order-taking.” Steve Henderson.
Not sure if my colleague Steve was the first person to say this, but he was the first person I ever heard say it.
“It’s time to start living the life you’ve imagined.” Henry James
“We meet no ordinary people in our lives.” CS Lewis
After Churchill, CS Lewis was the most frequently quoted thinker in Coffee in the Clouds. Lewis is probably most-well known today as the author of the Chronicles of Narnia (The Lion, the Witch and the Wardrobe books). He was an Oxford professor, philosopher and theologian, an Inkling, and friend of JRR Tolkien – they reviewed each other’s novels in progress at meetings of the Inklings.
I often say “Everyone is the hero of their own story” as a reminder to try to look at things from the other person’s perspective. Lewis takes that several steps further. If only we could remember this in every interaction with people and see their extraordinariness!
“Choose a job you love, and you will never have to work a day in your life.” — Confucius
“Start by doing what is necessary; then by doing what is possible; and suddenly you are doing the impossible.” St Francis of Assisi.
One of the roles I’ve had at multiple consulting firms was to take over projects that weren’t going well and getting them back on track. This quote really sums up my approach to managing those troubled project situations. Often the team is demoralized. They don’t believe in themselves or that the goals are achievable. Little victories start to bring them around and lead to bigger and bigger successes. Just achieve one small milestone. That’s enough to start.
“When you are running a business there is a constant need to reinvent oneself. One should have the foresight to stay ahead in times of rapid change and rid ourselves of stickiness in any form in the business.” Shiv Nadar.
“Adventures are never fun while you’re having them.” CS Lewis
“Better a diamond with a flaw than a pebble without.” Confucius
Or a “Dymond” with a flaw.
“Nothing limits achievement like small thinking; nothing expands possibilities like unleashed thinking.” William Arthur Ward via colleague Faridah Saadat
“You can do anything you decide to do. You can act to change and control your life; and the procedure, the process is its own reward.” Amelia Earhart
“There are many absolutely incredible women working from the grassroots up, whose life experiences, as well as their capabilities, more than qualify them for a voice at the table. Many are unheard heroines that keep peace within and across communities.” Sophie, Countess of Wessex
“If opportunity doesn’t knock; build a door.” Milton Berle
“If you see a turtle sitting on a fence post, the one thing you know for sure is that it didn’t get there by itself.” Steve Henderson
“Do not dare not to dare” CS Lewis
“The game is more than the player of the game, and the ship more than the crew.” Kipling
When I was a university student the Engineering library was temporarily in the old City of Toronto main library building. I liked to study at a desk that overlooked a large fireplace that had this quote carved above it. I probably spent as much time staring at the quote, trying to understand what Kipling was saying as I did on solving partial differential equations. With much the same lack of result!
Looking up the quote now, it is from the chorus of the poem “A Song in Storm”, which Kipling wrote in the period 1914-1918. The poem is about enduring using a travelling in a ship in a storm at sea as a metaphor.
“I hated every minute of training. but I said ‘don’t quit. Suffer now and live the rest of your life as a champion’”. Mohammed Ali
“Diversity is a fact, but inclusion is a choice we make every day. As leaders, we have to put out the message that we embrace, and not just tolerate, diversity.” Nellie Borrero of Accenture
For Pride month in June 2021 I looked for specific quotes about diversity. The next several represent those comments on diversity I thought most impactful.
“What’s often ignored is that diversity is not only a pipeline or recruiting issue. It’s an issue of making the people who do make it through the pipeline want to stay at your company.” Andrea Barrica
“A lot of different flowers make a bouquet.” Islamic Proverb
“Many conversations about diversity and inclusion do not happen in the boardroom because people are embarrassed at using unfamiliar words or afraid of saying the wrong thing — yet this is the very place we need to be talking about it. The business case speaks for itself — diverse teams are more innovative and successful in going after new markets.” Dame Inga Beale, former CEO of Lloyds of London.
“Diversity is the mix. Inclusion is making the mix work.” Andres Tapia
“Our ability to reach unity in diversity will be the beauty and the test of our civilization.” Mahatma Gandhi
“Diversity is not about how we differ. Diversity is about embracing one another’s uniqueness.” Ola Joseph
“It is time for parents to teach young people early on that in diversity there is beauty and there is strength.” Maya Angelou
“I’ve learned that lesson many times.” David Leaver (my nephew. This was said when he was a child.)
“If we let ourselves, we shall always be waiting for some distraction or other to end before we can really get down to our work. The only people who achieve much are those who want knowledge so badly that they seek it while the conditions are still unfavorable. Favorable conditions never come.” CS Lewis
“The man who moves a mountain begins by carrying away small stones.” Confucius
“Anyone can hold the tiller when the sea is calm.” Epictetus
Epictetus was a Greek Stoic Philosopher. Born a slave, he eventually was freed and founded a school of philosophy. One of my all-time favourite quotes. I read a book of his meditations early in my career, this one has stuck with me.
I think of this several ways; I’m sure that there are more.
The sailboat’s not going anywhere when the sea is calm, so it’s irrelevant who holds the tiller. With a favourable wind the boat can easily achieve its destination, with even someone reasonably competent at the helm. It’s when the seas are rough that we need our best person at the helm. A reminder not only to evaluate the results, but the situation and circumstances that led to those results. A reminder to assign people tasks aligned with their capabilities and capacity to grow too.
“Clouds came floating into my life, no longer to carry rain or usher storm, but to add color to my sunset sky.” Rabindaranath Tagnore
“The best time to plant a tree was 20 years ago. The second-best time is right now.” Steve Henderson
“Everyone thinks forgiveness is a lovely idea until he has something to forgive.” CS Lewis
“Don’t count the days, make the days count.” Muhammad Ali
“I’m a big fan of easy.” Gladys Dymond (my mother)
We were talking about ways to solve some small problem and there was one that was simpler and would take less time, but cost a little more. I thought since I was going to have to do the effort, I should try to save her the money. This was her reply. An important reminder to check the priorities and the budget! Also, the value of expediency.
“When you don’t know what to do, do something.” Gladys Dymond
Mom said this all the time when I was a kid. It drove me nuts. Now its my most frequently used quote from her. (I try to avoid “were you raised in a barn?”) Although I think prioritization is important, there are times when it’s just better to do anything. When you have 10,000 things to do and you do any one of them, you now have 9,999 things to do. Versus spending all day figuring out which one to do.
“We live, in fact, in a world starved for solitude, silence, and private: and therefore starved for meditation and true friendship.” CS Lewis
“There is not a human being on this planet that does not yearn for the deep reconciliation of the human spirit” Chief Joseph
Chief Dr Robert Joseph is ambassador for reconciliation Canada and member of National Assembly of First Nations. I looked for this quote and the ones that follow for the Canada’s first National Day for Truth and Reconciliation. https://reconciliationcanada.ca/
“The more you want to embrace the notion that you can indeed inspire change, the more power and courage you give yourself to act in the pursuit of justice and equality” Chief Joseph
“Reconciliation includes anyone with an open mind and an open heart who is willing to look into the future with a new way” Chief Joseph
“Let us find a way to belong to this time and place together. Our future, and the well-being of all our children, rests with the kind of relationships we build today” Chief Joseph
“The ultimate measure of a man is not where he stands in moments of comfort and convenience, but where he stands in times of challenge and controversy.” Martin Luther King
“Conviction is worthless unless it is converted into conduct”. Thomas Carlyle (via Forbes)
“Half of getting there is having the confidence to show up — and keep showing up.” Sophia Amoruso (via Forbes)



 and embedding a security perspective into it right from the start. Security is not a standalone practice but instead a shared responsibility. Designing and building security in rather than having it imposed by a separate ‘compliance’ function.
and embedding a security perspective into it right from the start. Security is not a standalone practice but instead a shared responsibility. Designing and building security in rather than having it imposed by a separate ‘compliance’ function. Successful implementations of DevOps change the Dev and Ops cultures to make sure we stop thinking either/or in order to get both rapid access to change and maintain production stability. They highly automate the steps of software creation and use from requirements definition through development, integration, testing, deploying and operating. They use combined processes and tools to shorten development cycles, and allows for more frequent deployment to production.
Successful implementations of DevOps change the Dev and Ops cultures to make sure we stop thinking either/or in order to get both rapid access to change and maintain production stability. They highly automate the steps of software creation and use from requirements definition through development, integration, testing, deploying and operating. They use combined processes and tools to shorten development cycles, and allows for more frequent deployment to production. 
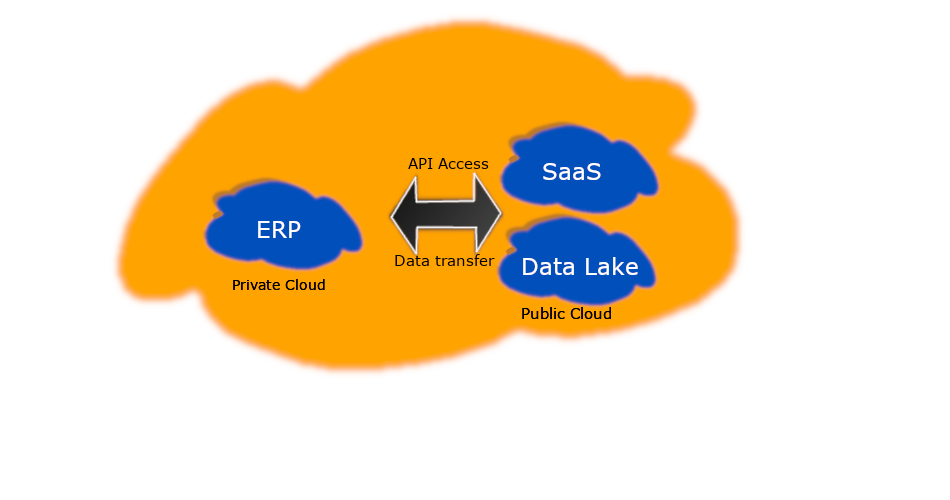
 Some Hybrid Cloud Examples
Some Hybrid Cloud Examples